语言unicode范围整理,国家unicode范围
”unicode 国家unicode 国家范围 中国unicode 语言范围“ 的搜索结果
当然可以通过直接判断Unicode码,但是鉴于习惯,以下提供的是Unicode码对应的数字区间。毕竟字符的本质也就是通过二进制进行存储编码的而已。基本汉字:[0x4e00,0x9fa5](或十进制[19968,40869])数字:[0x 0030,0x...
unicode 多国语言字库制作软件,免费注册,免费教学。
汉字unicode编码范围
Unicode 编码范围 各国文字 Unicode 编码范围 各国文字 Unicode 编码范围 各国文字 Unicode 编码范围 各国文字 Unicode 编码范围 各国文字 Unicode 编码范围 各国文字
通过unicode代码点判断字符串输入是何种语言
一、在C/C++控制台应用程序中使用Unicode的方法可能很多人都知道C/C++中Unicode字符串是wchar_t*,Unicode字符串常量是L"string",但是通常没办法在console中直接输出这些字符串,因为C/C++默认的设置是locale="C"(C...

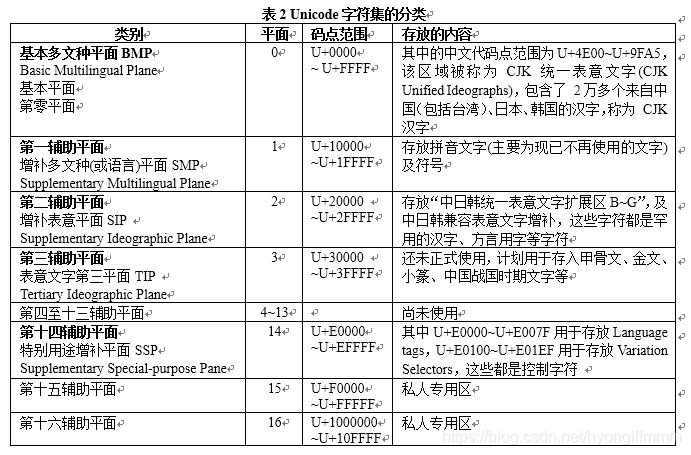
原文地址:http://blog.csdn.net/xzl04/article/details/6307416
unicode编码范围: 汉字:[0x4e00,0x9fa5](或十进制[19968,40869]) 数字:[0x30,0x39](或十进制[48, 57]) 小写字母:[0x61,0x7a](或十进制[97, 122]) 大写字母:[0x41,0x5a](或十进制[65, 90])
Unicode中文和特殊字符的编码范围 编程中有时候需要用到匹配中文的正则,一般用 [ \u4e00-\u9fa5]+ 即可搞定。不过这正则对一般的火星文鸟语就不太适用了,甚至全角的标点符号都不包含在内。例如游戏里面的玩家...

标准的现代维吾尔文字符集unicode编码表
unicode码的分布情况,够清楚了吧!不仅汉字,什么都有了! ******************************************************* 0000..007F; Basic Latin 0080..00FF; Latin-1 Supplement 0100..017F; Latin Extended-A ...
unicode介绍Unicode只是定义了一个字符和一个编码的映射,但是呢,对应的存储却没有制定。 比如一个编码0x0041代表大写字母A,那么可能有一种存储至少有4个字节,那可能0x00000041来存储代表A。 这个就是unicode的...
想到了之间学习 ES6 时关于字符串的 Unicode 表示法,突然就很想知道 UTF-16 是如何进行编码的,我尝试将一些汉字转换成二进制数,然后简单的按 2 个字节一组转换成十六进制,发现对于那些码点较大的汉字,结果
C# 实现 Unicode 字符串 转换 啥也不多说,直接上干货 /// <summary> /// 对正常的字符串转换为 Unicode 的字符串 /// </summary> /// <param name="normalStr">正常的字符串</param> ...
作为最为广泛使用的办公软件之一...然而,尽管word官方已经宣布支持latex格式的公式,并非所有版本的word都支持latex,并且word自带的UnicodeMath格式在简洁和直观性上更胜一筹。因此,撰写了这篇博客供需要的朋友参考
经常要使用过滤中文,过滤标点符号之类的正则表达式,这里对查到的字符...完整的CJK Unicode范围(5.0版) 转自 https://blog.oasisfeng.com/2006/10/19/full-cjk-unicode-range/ 因为FontRouter新版本开发的需要,在
Unicode的编码方式参见: https://blog.csdn.net/m372897500/article/details/37592543 十进制 十六进制 字符数 编码分类(中文) 编码分类(英文) 起始 终止 起始 终止 (个) 0 127 0000 007F 128 C0控制符及...

在Windows的控制面板中,“区域与语言选项”有一个功能,类似于Apploc程序,比如说:让那些本来是繁体界面的程序,在简体系统中也能够正常地显示出來,而不是乱码。 但是如果操作系统安装时为GHOST,那么C:\WINDOWS\...
Unicode中文和特殊字符的编码范围 根据Unicode5.0整理如下: 1)标准CJK文字 http://www.unicode.org/Public/UNIDATA/Unihan.html 2)全角ASCII、全角中英文...
各个国家 不同字符集的unicode 编码范围 找到一篇好文,存着自己用用(^-^)V 另外印度语/印地语utf-8编码是 0900-097F:天城文书 (Devanagari) 它是根据文字类型来分段的,不一定是地区名哦...
越南的Unicode范围分为好几段 https://unicode-table.com/cn/blocks/enclosed-cjk-letters-and-months/ 需要自己从拉丁语附属语言中挑选。比较麻烦 或者让策划给表,列出所有Unicode值。 转载于:...

记录: BasicLatin(U+0000-007F) LatinExtended-A(U+0100-017F) LatinExtendedAdditional(U+1E00-1EFF) CombiningDiacriticalMarks(U+0300-036F) CombiningDiacriticalMarksSupplement(U+1DC0-1DFF) ...
十六进制表示法 \u4e00-\u9fa5
推荐文章
- Java面向对象程序设计 第七章总结_方法的返回值被错误地处理为一个非空的对象-程序员宅基地
- RFX2401C skyworks射频2.4GHZ ZIGBEE/ISM发射/接收RFeIC_rfx2401c csdn-程序员宅基地
- Lambda简便方法引用、构造方法引用_lambdautils.getname-程序员宅基地
- sql表格模型获取记录内容_SQL Server和BI –如何使用Excel记录表格模型-程序员宅基地
- GateWay配置_grateway配置-程序员宅基地
- 云栖专辑| 阿里毕玄:程序员的成长路线-程序员宅基地
- Android 导出traces.txt 遇到的坑_biotraces无法导出-程序员宅基地
- 【ffmpeg 给视频添加背景音乐,去掉视频背景音乐原声】_ffmpeg.net 视频 加入 音频-程序员宅基地
- cocos2d-x3.2 lua 返回键监听_cocos2dx-lua cc.director:getinstance():endtolua()-程序员宅基地
- etcc oracle ebs,Oracle EBS12.2.6 克隆问题集合-程序员宅基地